ABSTRACT
We introduce Kimi K2, a Mixture-of-Experts (MoE) large language model with 32 billion activated parameters and 1 trillion total parameters. We propose the MuonClip optimizer, which improves upon Muon with a novel QK-clip technique to address training instability while enjoying the advanced token efficiency of Muon.
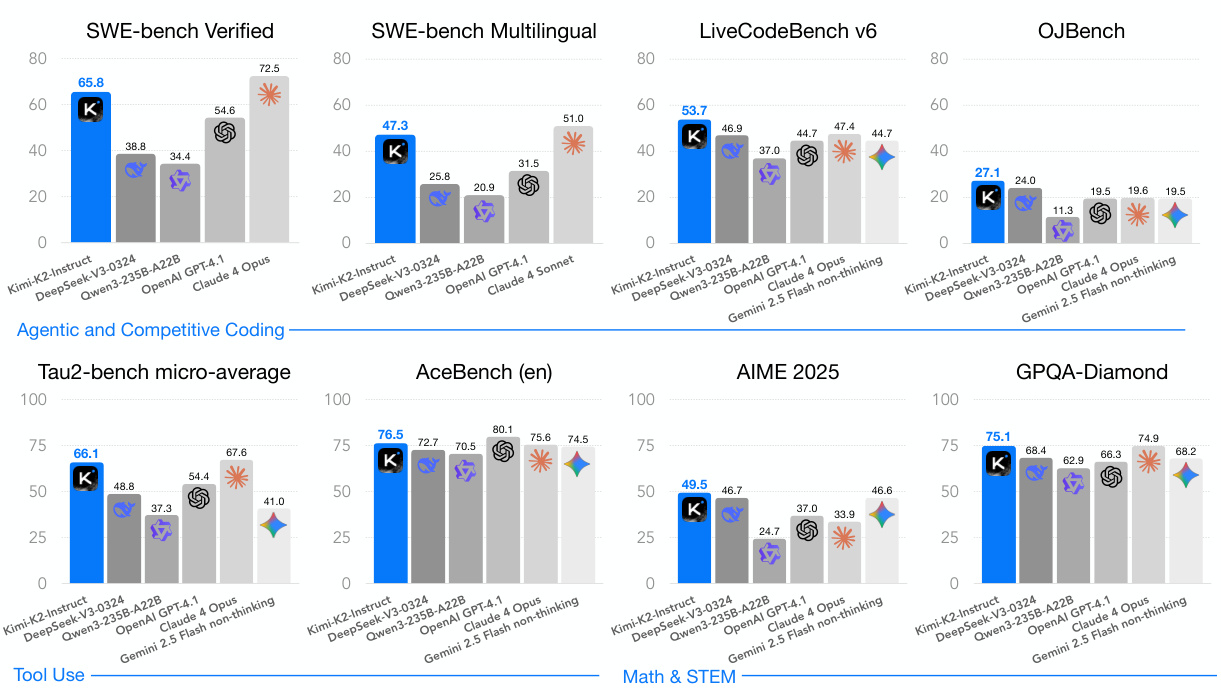
Kimi K2 achieves state-of-the-art performance among open-source non-thinking models, with strengths in agentic capabilities. Notably, K2 obtains 66.1 on Tau2-Bench, 76.5 on ACEBench (En), 65.8 on SWE-Bench Verified, and 47.3 on SWE-Bench Multilingual — surpassing most open and closed-sourced baselines in non-thinking settings.
KEY HIGHLIGHTS
1.04 Trillion Parameters - MoE architecture with 32B activated parameters
15.5 Trillion Tokens - Pre-trained with zero loss spikes
Agentic Capabilities - Superior performance in software engineering and agentic tasks